The task undertaken by our team was the LongEval-Retrieval Task at CLEF 2023. This task focused on evaluating the temporal persistence of Information Retrieval (IR) systems when applied to corpora acquired at different timestamps. The goal was to develop an IR system capable of handling changes over time in web document collections and maintaining its retrieval effectiveness longitudinally. Participants were provided with evolving test collections derived from a French web search engine (Qwant), with the expectation that systems would remain persistent in their retrieval effectiveness across monthly snapshots of documents and queries. The task aimed to explore how the performance of IR systems changes as the underlying document collection evolves over short-term and long-term periods.
Our team's approach to this task involved building a search engine that utilized query expansion techniques and a reranking mechanism to enhance retrieval performance and temporal robustness. Our methodology included several key components:
- Parsing and Indexing: We developed a custom parser to process documents in the TREC format and implemented custom analyzers for both French and English languages, considering tokenization, character folding, elision/possessive removal, stopword removal (using default and custom stoplists), position filtering, and stemming (Snowball, Light, and Krovetz stemmers were explored). The indexing process created a searchable database storing term frequencies and positions.
- Initial Retrieval with BM25: As a base retrieval function, we employed Okapi BM25 due to its efficiency and effectiveness, and we also experimented with tuning its parameters. We also explored a boolean query approach.
- Query Expansion: To improve search relevance, FADERIC implemented several query expansion techniques, including:
- Fuzzy search to allow for approximate matches.
- Word N-grams (Shingles) to capture local relationships between words in queries (up to 3 words).
- Synonym expansion using both a custom synonym list and WordNet integrated with OpenNLP Part of Speech (PoS) tagging to address polysemy.
- Reranking: To further enhance the ranking quality, we incorporated a passage reranking stage using transformer-based models from the PyGaggle library. We experimented with pretrained T5 and BERT models and even attempted to fine-tune our own BERT model on the provided data. We developed a method to integrate the scores from the reranker with the initial BM25 scores. A key challenge was the integration of our Python-based reranker with our Java-based search engine, which we addressed using the JEP library.
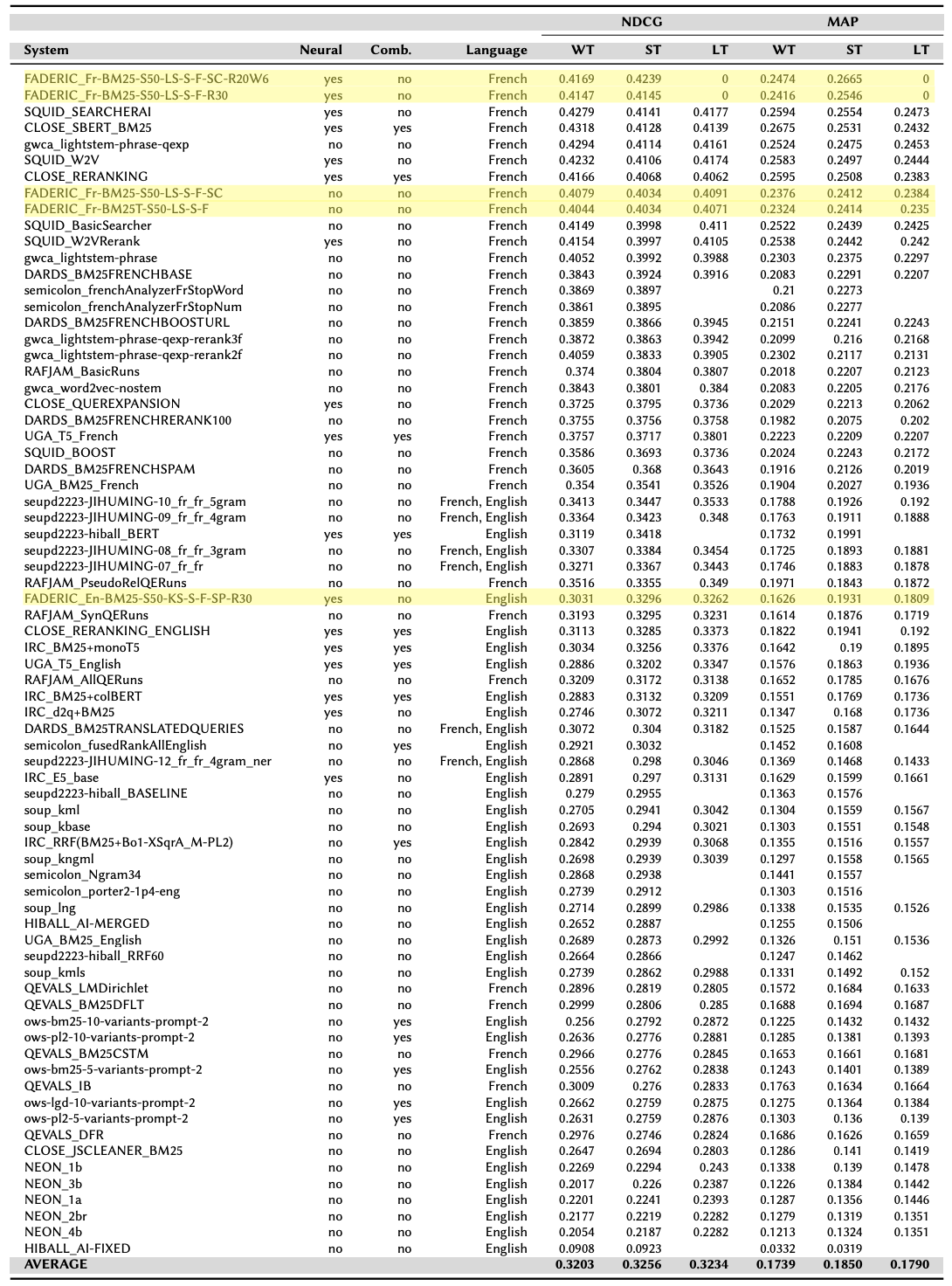
The results obtained by our team demonstrated the effectiveness of our approach. Our experiments on the training collection showed that combining different components, particularly query expansion and reranking, led to significant performance improvements in terms of nDCG and MAP. We observed that runs on the French collections consistently outperformed those on the English collections, likely due to issues with the automatic translation of the document corpus. The submitted systems, evaluated on the heldout, short-term, and long-term test collections, generally showed a performance drop from the training data, which was expected. However, our analysis of the test results indicated that our system maintained satisfactory performance over time, with no significant worsening in the short term and only a moderate performance drop in the long term. Statistical analysis (ANOVA2 and Tukey's HSD) was conducted on the French runs to assess the significance of performance differences across the heldout, short-term, and long-term collections. Our findings highlighted the crucial role of query expansion and reranking in building robust IR systems capable of handling the temporal dynamics of information retrieval. Our best-performing submission utilized a combination of BM25, custom stopword list, light stemming, shingle-based query expansion, fuzzy matching, custom synonyms, and a BERT-based reranker, demonstrating the benefit of integrating various IR techniques and neural models.
In general, our system achived the best overall performance of all submitted systems, as can be seen in the figure below, excluding the LT dataset, for which there was a submission error. More details on our approach can be found in the proceedings paper while the full results and more comments for the competition in the overview paper of the competition.