Select Connection: INPUT[inlineListSuggester(optionQuery(#permanent_note), optionQuery(#literature_note), optionQuery(#fleeting_note)):connections]
Table of Contents
Sequence Models have been motivated by the analysis of sequential data such text sentences, time-series and other discrete sequences data. These models are especially designed to handle sequential information while Convolutional Neural Network are more adapted for process spatial information.
Basic Model
Suppose a translation from French to English example. A first RNN could take care of encoding the input, this outputs a vector which will be fed to the decoder with a second RNN
Components:
- Encoding network
- Decoding network
This basic model could also work for Image captioning:
- learn an encoding with a convolutional network
- concatenate a RNN to generate an output which is a set of words
→ in the next section we will explore how to get not a random output (like in this basic model), but the most likely
Picking the Most Likely Sentence
The basic model described above is very similar to a Language Model, with the only difference that the input is a vector processed by another network. For this reason we will call the “machine translation” model Conditional Language Model, which compute:
What we want now is To do it we will use an algorithm called Beam Search.
A greedy approach will not work, will return less optimal sentences.
Beam Search
It has an hyperparameter (Beam Width), which regulates how many words we should keep. At the first step, the algorithm takes the most likely words, at the second step it takes the most likely words for each of the words taken at the last step, continues like this for every position.
For the decoder, at each position it will output:
Some refinements:
Length Normalization
instead of maximizing the product:
which could give very small numbers and lead to errors due to numerical rounding of floating point numbers, in practice the log scale is used like this:
Also, to avoid that longer sequences get small probabilities, we multiply the factor , usually with .
Discussion
Beam width :
- large : better result, slower
- small : worse result, faster
- usually around 10, 100 is considered very large
Beam search runs faster than other search algorithms, but does not guarantee to find the exact maximum.
Error Analysis
human: algorithm:
Cases:
- , beam search is at fault
- , is a better translation than , so RNN model is at fault
for each dev set example, do this comparison and see who is at fault. If you find Beam Search is at fault → increase beam width else → deeper analysis to see if apply regularization and other ML techniques
Bleu Score
When you have multiple great answers, how do you measure accuracy?
BLEU (BiLingual Evaluation Understanding) could be a substitute to having humans evaluate each output.
As an example on Bigrams (pairs of words), consider the following references: Reference 1: The cat is on the mat Reference 2: There is a cat on the mat and the algorithm output: Output: The cat the cat on the mat
| count | count_{clip} | |
|---|---|---|
| the cat | 2 | 1 |
| cat the | 1 | 0 |
| cat on | 1 | 1 |
| on the | 1 | 1 |
| the mat | 1 | 1 |
| so the precision is , |
- , total number of bigrams in the output
- , maximum number of bigrams of all references
on unigrams:
more generally, on n-grams:
We can also define the Combined Blue score on multiple ngrams:
is the brevity penalty, defined as:
which penalizes shorter translations.
Attention Model
Usually, with short sentences and sentences that are too long the model performs poorly. The intuition is that a human translator translates a small part, than reads the next and translates and goes on until it is done.
Computes a set of attention weights , which says how much attention word needs with respect to word . This repeats for each word of the input.
the context will be the weighted sum:
with the constraint that .
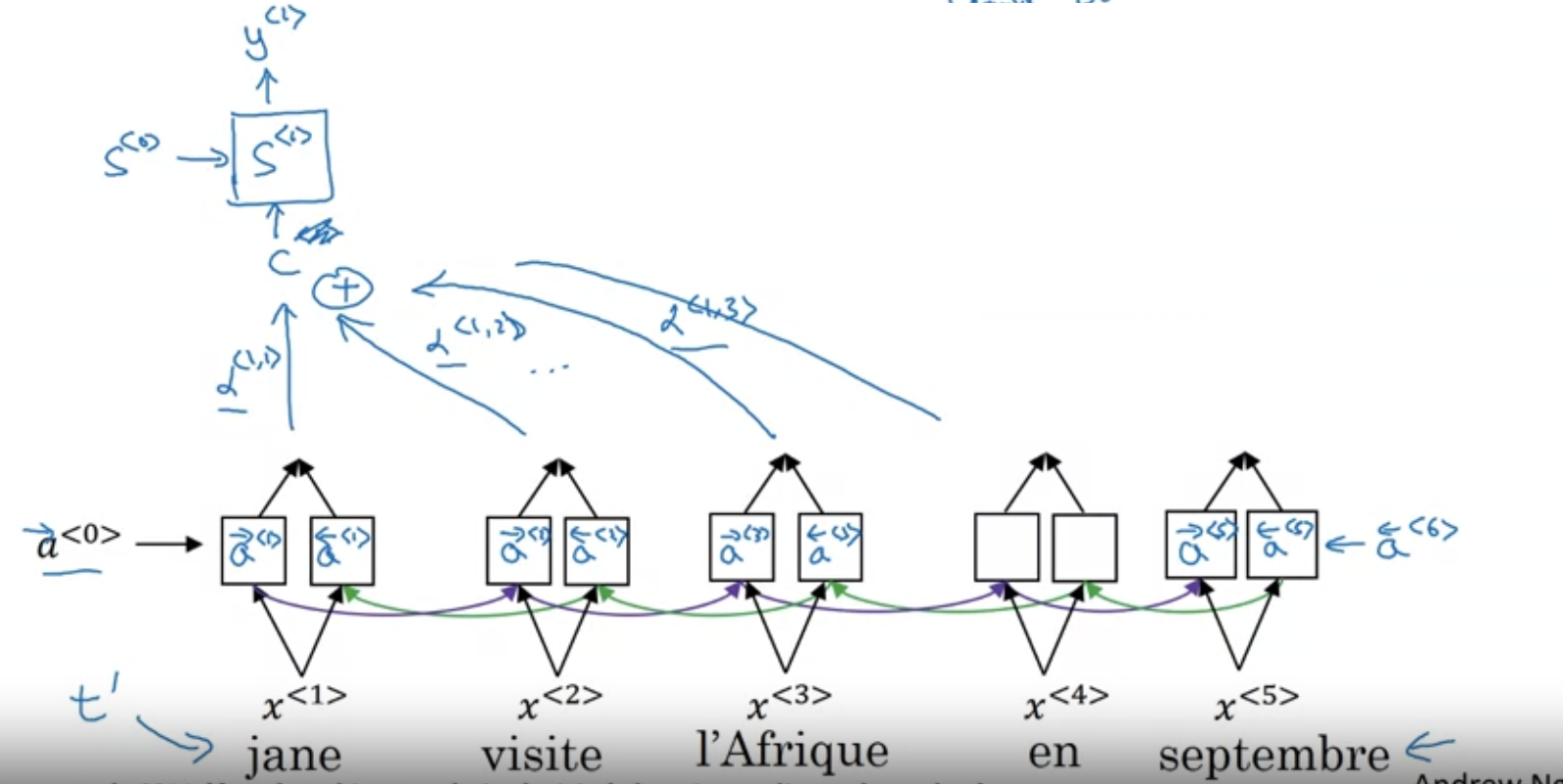
Computing attention
parameters can be computed with a small Neural Network with inputs and .
One downside is the quadratic time of the algorithm.